
Oh what a wild ride the last few weeks have been. The One Billion Row Challenge (1BRC for short), something I had expected to be interesting to a dozen folks or so at best, has gone kinda viral, with hundreds of people competing and engaging. In Java, as intended, but also beyond: folks implemented the challenge in languages such as Go, Rust, C/C++, C#, Fortran, or Erlang, as well databases (Postgres, Oracle, Snowflake, etc.), and tools like awk.
It’s really incredible how far people have pushed the limits here. Pull request by pull request, the execution times for solving the problem layed out in the challenge — aggregating random temperature values from a file with 1,000,000,000 rows — improved by two orders of magnitudes in comparison to the initial baseline implementation. Today I am happy to share the final results, as the challenge closed for new entries after exactly one month on Jan 31 and all submissions have been reviewed.
Results
So without further ado, here are the top 10 entries for the official 1BRC competition. These results are from running on eight cores of a 32 core AMD EPYC™ 7502P (Zen2) machine:
| # | Result (m:s.ms) | Implementation | JDK | Submitter |
|---|---|---|---|---|
1 |
00:01.535 |
21.0.2-graal |
||
2 |
00:01.587 |
21.0.2-graal |
||
3 |
00:01.608 |
21.0.2-graal |
||
00:01.880 |
21.0.1-open |
|||
00:01.921 |
21.0.2-graal |
|||
00:02.018 |
21.0.2-graal |
|||
00:02.157 |
21.0.2-graal |
|||
00:02.319 |
21.0.2-graal |
|||
00:02.332 |
21.0.2-graal |
|||
00:02.367 |
21.0.1-open |
You can find the complete result list with all 164 submissions as well as the description of the evaluation process in the 1BRC repository.
Congratulations to the implementers of the top three entries (Thomas Wuerthinger/Quan Anh Mai/Alfonso² Peterssen, Artsiom Korzun, and Jaromir Hamala), as well as everyone else one the leaderboard for putting in the effort to participate in this challenge! For the fun of it, and as a small expression of my appreciation, I have created a personalized "certificate" PDF for each accepted submission, stating the author’s name and time. You can find it at your entry in the leaderboard table.

Initially I had meant to pay for a 1️⃣🐝🏎️ t-shirt for the winner out of my own pocket. But then I remembered I have a company credit card ;) So I will actually do t-shirts for the Top 3 and a 1BRC coffee mug for the Top 20. I will follow up with the winners on the details of getting these to you shortly. Thanks a lot to my employer Decodable (we build a SaaS for real-time ETL and stream processing, you should totally check us out!) for sponsoring not only these prizes, but also the evaluation machine. It means a lot to me!
I am planning to dive into some of the implementation details in another blog post,
there is so much to talk about: segmentation and parallelization, SIMD and SWAR, avoiding branch mispredictions and spilling, making sure the processor’s pipelines are always fully utilized, the "process forking" trick, and so much more.
For now let me just touch on two things which stick out when looking at the results.
One is that all the entries in the Top 10 are using Java’s notorious Unsafe class for faster yet unsafe memory access.
Planned to be removed in a future version, it will be interesting to see which replacement APIs will be provided in the JDK for ensuring performance-sensitive applications like 1BRC don’t suffer.
Another noteworthy aspect is that with two exceptions all entries in the Top 10 are using GraalVM to produce a native binary. These are faster to start and reach peak performance very quickly (no JIT compilation). As the result times got down to less than two seconds, this makes the deciding difference. Note that other entries of the contest also use GraalVM as a JIT compiler for JVM-based entries, which also was beneficial for the problem at hand. This is a perfect example for the kind of insight I was hoping to gain from 1BRC. A special shout-out to Serkan Özal for creating the fastest JVM-based solution, coming in on a great fourth place!
Bonus Result: 32 Cores, 64 Threads
For officially evaluating entries into the challenge, each contender was run on eight cores of the target machine. This was done primarily to keep results somewhat in the same ballpark as the figures of the originally used machine (I had to move to a different environment after a little while, re-evaluating all the previous entries).
But it would be a pity to leave all the 24 other cores unused, right? So I ran the fastest 50 entries from the regular evaluation on all 32 cores / 64 threads (i.e. SMT is enabled) of the machine, with turbo boost enabled too, and here is the Top 10 from this evaluation (the complete result set for this evaluation can be found here):
| # | Result (m:s.ms) | Implementation | JDK | Submitter |
|---|---|---|---|---|
1 |
00:00.323 |
21.0.2-graal |
||
2 |
00:00.326 |
21.0.2-graal |
||
3 |
00:00.349 |
21.0.2-graal |
||
00:00.351 |
21.0.2-graal |
|||
00:00.389 |
21.0.2-graal |
|||
00:00.408 |
21.0.2-graal |
|||
00:00.415 |
21.0.2-graal |
|||
00:00.499 |
21.0.2-graal |
|||
00:00.602 |
21.0.1-graal |
|||
00:00.623 |
21.0.1-open |
The fastest one coming in here is Jaromir Hamala, whose entry seems to take a tad more advantage of the increased level of parallelism. I’ve run this benchmark a handful of times, and the times and ordering remained stable, so I feel comfortable about publishing these results, albeit being very, very close. Congrats, Jaromir!
Bonus Result: 10K Key Set
One thing which I didn’t expect to happen was that folks would optimize that much for the specific key set used by the example data generator I had provided. While the rules allow for 10,000 different weather station names with a length of up to 100 bytes, the key set used during evaluation contained only 413 distinct names, with most of them being shorter than 16 bytes. This fact heavily impacted implementation strategies, for instance when it comes to parsing rows of the file, or choosing hash functions which work particularly well for aggregating values for those 413 names.
So some folks asked for another evaluation using a data set which contains a larger variety of station names (kudos to Marko Topolnik who made a strong push here). I didn’t want to change the nature of the original task after folks had already entered their submissions, but another bonus evaluation with 10K keys and longer names seemed like a great idea. Here are the top 10 results from running the fastest 40 entries of the regular evaluation against this data set (all results are here):
| # | Result (m:s.ms) | Implementation | JDK | Submitter |
|---|---|---|---|---|
1 |
00:02.957 |
21.0.2-graal |
||
2 |
00:03.058 |
21.0.2-graal |
||
3 |
00:03.186 |
21.0.2-graal |
||
00:03.998 |
21.0.2-graal |
|||
00:04.042 |
21.0.2-graal |
|||
00:04.289 |
21.0.1-open |
|||
00:04.522 |
21.0.2-graal |
|||
00:04.653 |
21.0.2-graal |
|||
00:04.733 |
21.0.1-open |
|||
00:04.836 |
21.0.1-graal |
This evaluation shows some interesting differences to the other ones. There are some new entries to this Top 10, while some entries from the original Top 10 do somewhat worse for the 10K key set, solely due to the fact that they have been so highly optimized for the 413 stations key set. Congrats to Artsiom Korzun, whose entry is not only the fastest one in this evaluation, but who also is the only contender to be in the Top 3 for all the different evaluations!
Thank You!
The goal of 1BRC was to be an opportunity to learn something new, inspire others to do the same, and have some fun along the way. This was certainly the case for me, and I think for participants too. It was just great to see how folks kept working on their submissions, trying out new approaches and techniques, helping each other to improve their implementations, and even teaming up to create joint entries. I feel the decision to allow participants to take inspiration from each other and adopt promising techniques explored by others was absolutely the right one, aiding with the "learning" theme of the challenge.
I’d like to extend my gratitude to everyone who took part in the challenge: Running 1BRC over this month and getting to experience where the community would go with this has been nothing but absolutely amazing. This would not have been possible without all the folks who stepped up to help organize the challenge, be it by creating and extending a test suite for verifying correctness of challenge submissions, setting up and configuring the evaluation machine, or by building the infrastructure for running the benchmark and maintaining the leaderboard. A big shout-out to Alexander Yastrebov, Rene Schwietzke, Jason Nochlin, Marko Topolnik, and everyone else involved!
A few people have asked for stats around the challenge, so here are some:
-
587 integrated pull requests, 164 submissions
-
61 discussions, including an amazing "Show & Tell" section where folks show-case their non-Java based solutions
-
1.1K forks of the project
-
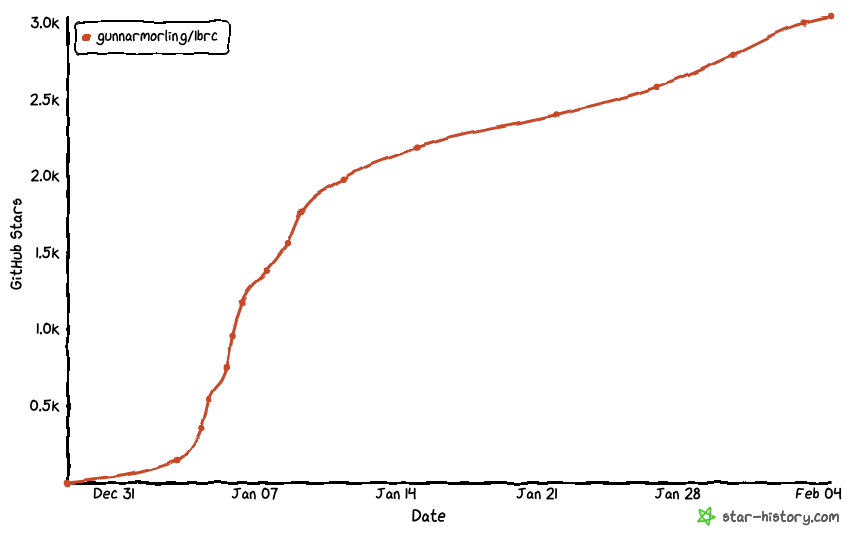
3K star-gazers of the project, with the fastest growth in the second week of January
-
1,909 workflow runs on GitHub Actions (it would have been way more, had I set up an action for running the test suite against incoming pull requests earlier, doh)
-
187 lines of comment in the entry of Aleksey Shipilëv
-
188x speed-up improvement between the baseline implementation and the winning entry
-
~100 consumed cups of coffee while evaluating the entries
Lastly, here are some more external resources on 1BRC, either on the challenge itself or folks sharing their insights from building a solution (see here for a longer list of blog posts and videos):
-
Cliff Click discussing his 1BRC solution on the Coffee Compiler Club (video)
-
The One Billion Row Challenge Shows That Java Can Process a One Billion Rows File in Two Seconds (interview by Olimpiu Pop)
-
One Billion Row Challenge (blog post by Ragnar Groot Koerkamp)
Which Challenge Will Be Next?
Java is alive and kicking! 1BRC has shown that Java and its runtime are powerful and highly versatile tools, suitable also for tasks where performance is of uttermost importance. Apart from the tech itself, the most amazing thing about Java is its community though: it sparked a tremendous level of joy to witness how folks came together for solving this challenge, learning with and from each other, sharing tricks, and making this a excellent experience all-around.
So I guess it’s just natural that some folks asked whether there’d be another challenge like this any time soon, when it is going to happen, what it will be about, etc. Someone even stated they’d take some time off January next year to fully focus on the challenge :)
I think for now it’s a bit too early to tell what could be next and I’ll definitely need a break from running a challenge. But if a team came together to organize something like 1BRC next year, with a strong focus on running things in an automated way as much as possible, I could absolutely see this. The key challenge (sic!) will be to find a topic which is equally as approachable as this year’s task, while providing enough opportunity for exploration and optimization. I am sure the community will manage to come up with something here.
For now, congrats once again to everyone participating this time around, and a big thank you to everyone helping to make it a reality!
1️⃣🐝🏎️