

That guy above? Yep, that’s me, whenever someone says "Kafka queue". Because, that’s not what Apache Kafka is. At its core, Kafka is a distributed durable event log. Producers write events to a topic, organized in partitions which are distributed amongst the brokers of a Kafka cluster. Consumers, organized in groups, divide the partitions they process amongst themselves, so that each partition of a topic is read by exactly one consumer in the group.
This partition-based design defines two of Kafka’s key characteristics:
-
The maximum degree of consumer parallelism: Each partition is processed by not more than one consumer; in order to increase the number of consumers processing a topic, it needs to be split up into more partitions, which implies a potentially costly repartitioning operation for existing topics with a large amount of data.
-
Ordered processing of messages: All messages with the same partitioning key will be sent to the same partition which is processed by a single consumer.
These semantics make Kafka a great foundation for a large variety of high volume data streaming use cases such as click stream processing, metrics and log ingestion, real-time ETL and analytics, microservices data exchange, fraud detection, and many more. On the flip side, Kafka, as is, is not a good fit for use cases requiring queuing semantics, where you’d like to process messages one by one, potentially scaling out consumers way beyond the number of partitions in a topic. In particular, consumers as of today commit the progress they’ve made within a partition by means of persisting the offset of the last message they’ve processed. It is not possible to acknowledge or reject individual messages. This leads to a problem known as "head-of-line blocking": if a given message can’t be consumed for whatever reason, or if it just takes very long to do so, that consumer can’t easily move beyond of that message.
|
In Kafka terminology, the elements of a topic are referred to as "record", with "message" oftentimes being used interchangeably. Personally, I am using the former when referring to the technical concept of an entry of a log, whereas I’m using "message" (or "event", depending on the specific use case) when discussing the semantic entity which is represented by a record. |
One common example for this is job queueing: you’d like to submit unrelated work items to a queue, from where they are picked up and processed as quickly as possible by a set of independent workers. Each item should be processed in isolation, i.e. while one worker is consuming an item from the queue, another worker should be able to pick up the next one in parallel, without having to await successful handling of the first one. If there’s many work items, or if they take a longer time to process, it should be able to add more workers to ensure a reasonable overall throughput of the system. A work item which cannot be processed for some reason should not hold up the processing of subsequent items.
While some efforts were made to support this kind of use case when using Kafka, for instance in the form of Confluent’s parallel consumer, actual queue implementations such as ActiveMQ Artemis or RabbitMQ were traditionally better suited for this. To learn more about the fundamental differences between event logs and queues, and why it can be interesting to implement the latter on top of the former, refer to this excellent blog post by Jack Vanlightly.
As of Kafka 4.0—due in a couple of weeks—things will change though: after two years of work, an Early Access of KIP-932: Queues for Kafka is part of this release. It promises to add queue-like semantics to Kafka. Let’s take a look!
Towards Queue Support in Kafka—Introducing Share Groups
At the core of KIP-932 are so-called share groups : expanding the existing notion of Kafka consumer groups, a share group is a set of cooperative consumers processing the messages from a topic. Unlike consumer groups though, multiple members of a share group can process the messages on one and the same partition. This means that there can be more (active) members in a share group than there are partitions, and a high degree of consumer parallelism can be achieved also when having just a few or even only a single partition. Membership in a share group is coordinated using the new consumer rebalance protocol introduced in Kafka 4.0 via KIP-898. A partition consumed by a share group is called a share partition.
Messages can be acknowledged individually, allowing for much more flexibility than the offset-based approach of consumer groups. A broker-side component called the share-partition leader manages the state of in-flight messages, distributing them to the members of the share group. The share-partition leader is co-located with the leader of the partition, i.e. it’s currently not supported to use share groups and thus Kafka queues when reading from a follower node in the Kafka cluster.
The messages in a share-partition go through a life cycle of distinct states as shown below:
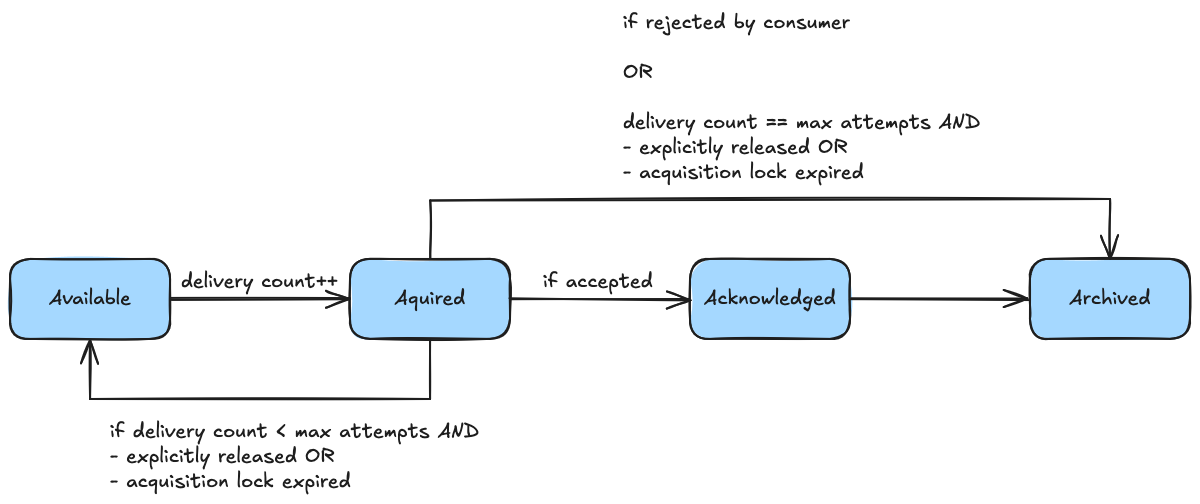
The share-partition leader processes messages which are eligible for consumption on a share-partition via a sliding window, demarcated by a lower offset called the share-partition start offset (SPSO) and a higher offset called the share-partition end offset (SPEO) . All messages before the SPSO are in the Archived state, all messages after the SPEO are in Available state. The messages within the window are called in-flight messages. When a consumer fetches messages, the leader will search for available messages in the in-flight window, mark them as acquired, and return them in a batch to the consumer. To limit memory consumption on the broker, the maximum number of messages in Acquired state can be controlled via the group.share.partition.max.record.locks configuration setting. When processing a message, a consumer may
-
acknowledge it as successfully consumed, transitioning it to
Acknowledgedstate, -
release it, transitioning it back to
Availablestate and thus making it available for redelivery, or -
reject it, transitioning it to
Archivedstate, marking it as unprocessable.
Every message has a delivery counter, which gets increased each time it gets acquired. The maximum number of deliveries is limited using the group.share.delivery.attempt.limit broker option, preventing an infinite retry loop of consuming some unprocessable message ("poison pill").
One key aspect to understand is that the specific message states exist exclusively within the scope of a specific share group; this means that for instance a message may be rejected by one share group but be processed successfully by another. A share group may also be reset, allowing it to reprocess all the messages of a topic, or all the messages after a given timestamp. The Kafka distribution provides a new script, bin/kafka-share-groups.sh , for this purpose.
As the available messages on a share-partition are distributed amongst the members of the share group, there’s no guarantee in regards to the order of processing. Depending on specific timing behaviors, potential retries, etc., messages with higher offsets may be consumed before messages with lower offsets in the same partition. This is in stark contrast to how traditional Kafka consumer groups work, where the messages in one partition are always consumed in order of increasing offset. The KIP mentions that ordering of messages within a single batch is guaranteed to be in increasing offset order, but I’m not sure how useful this is going to be in practice, given consumers lack control over which messages end up in a given batch.
On the other hand it could be very useful for certain use cases to have guaranteed ordering for the messages with one and the same key. Consider for instance an ETL use case consuming data change events produced by a CDC tool such as Debezium. The source record’s primary key is used as the Kafka message key in this scenario, ensuring all change events for a given record are written to the same partition of the corresponding Kafka topic. With regular consumer groups, ordering of events for the same key is ensured, which is vital to make sure that the destination of such a pipeline receives the change events in the correct order, for instance when considering two subsequent updates to a record.
But arguably, the partition-based ordering is too coarse-grained in this scenario, as the order of events across keys typically doesn’t matter (and where it does matter, it would have to be global for the entire topic, not just a single partition). This comes at the price of reduced flexibility to parallelize and scale out the consumer, as described above. In contrast, share groups essentially don’t provide strong ordering guarantees, making them not suitable for this use case. If there was support for strong key-based ordering, that’d be a very useful middle ground between scalability and the provided semantics. It would be great to see this in a future version of queue support for Apache Kafka.
Share Groups in Action
Let’s shift gears a bit and take a look at how share groups can be used from within a Java application. At the time of writing, there’s no preview build of Apache Kafka 4.0 available yet, so I’ve built Kafka and its client libraries from source, which luckily is as straight forward as running the following:
1
./gradlew releaseTarGz publishToMavenLocal
This will yield a Kafka distribution archive under core/build/distributions/kafka_2.13-4.1.0-SNAPSHOT and install the client libraries into the local Maven repository.
As of the Kafka 4.0 release, share groups are an early access feature, not meant for production usage yet. As such, the feature needs to be enabled explicitly. To do so, add the following settings to your broker configuration file (for more details, see the release notes as well as the KIP, which provides a list of all new configuration options added for share group support):
1
2
unstable.api.versions.enable=true
group.coordinator.rebalance.protocols=classic,consumer,share
The Kafka client library contains a new API, KafkaShareConsumer, which exposes the new queue and share group semantics. Its overall programming model is very similar to the existing KafkaConsumer API, simplifying the transition from one to the other. For console-based access, the Kafka distribution contains a new shell script, kafka-console-share-consumer.sh , similar to kafka-console-consumer.sh known from previous Kafka versions.
The share consumer supports two working modes: implicit and explicit acknowledgement of messages. When using implicit mode, message acknowledgements will be committed automatically for the entire batch of messages processed by the consumer. In the simplest case, this happens for the previous batch when calling poll() again:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "my-share-group");
KafkaShareConsumer<String, String> consumer =
new KafkaShareConsumer<>(
props, new StringDeserializer(), new StringDeserializer());
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(
Duration.ofMillis(100)); (1)
for (ConsumerRecord<String, String> record : records) {
process(record);
}
}
| 1 | Fetch the next batch of messages, implicitly acknowledging the messages of the previous batch |
This approach lacks fine-grained control over acknowledgements, but it can be interesting if your primary interest in using share groups is to increase the number of workers in a consumer group beyond the partition count. For a typical queueing use case however, you’ll want message-level acknowledgements. This can be achieved via the ShareConsumer::acknowledge() method. It takes a record and an acknowledge type:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
while (true) {
ConsumerRecords<String, String> records = consumer.poll(
Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
if (isProcessable(record)) {
process(record);
consumer.acknowledge(record, AcknowledgeType.ACCEPT); (1)
}
else if (isRetriable(record)) {
consumer.acknowledge(record, AcknowledgeType.RELEASE); (1)
}
else {
consumer.acknowledge(record, AcknowledgeType.REJECT); (1)
}
}
consumer.commitSync(); (2)
}
| 1 | Acknowledge a message |
| 2 | Synchronously commit the acknowledgement state of all messages of the batch |
The acknowledge type can be one of the following:
-
ACCEPT, if the message could be processed successfully -
RELEASE, if the message cannot be processed due to some transient error, i.e. it may be processed successfully when retrying later on -
REJECT, if the the message cannot be processed and also is not retriable
The acknowledgement status for a given message will only be actually committed by calling commitSync(). If the consumer crashes after calling acknowledge() but before the commit happens, all messages from the batch will be presented to a consumer of the group again. When not calling commitSync(), the next invocation of poll() will commit automatically. This happens asynchronously though, which means you might receive a new batch of messages while the commit of the acknowledgement status of a previous batch fails.
When releasing a message for retrying, it will be part of a subsequent batch until the maximum delivery count for the message has been reached, in which case it will transition to Archived state, without having been processed. If required, a messages delivery count can be obtained from the ConsumerRecord. This allows you for instance to log a record when it hits the retry limit before archiving it.
Newly created share groups start processing from the latest offset by default. If you want it to start from the beginning of the input topic(s) instead, you need to set the newly added configuration property share.auto.offset.reset to earliest. Unlike the well-known auto.offset.reset option, this is not a consumer configuration option, but a group configuration option. You can use the AdminClient API for setting it:
1
2
3
4
5
6
7
8
9
10
11
12
13
try (AdminClient client = AdminClient.create(adminProperties)) {
ConfigEntry entry = new ConfigEntry("share.auto.offset.reset",
"earliest");
AlterConfigOp op = new AlterConfigOp(entry, AlterConfigOp.OpType.SET);
Map<ConfigResource, Collection<AlterConfigOp>> configs = Map.of(
new ConfigResource(
ConfigResource.Type.GROUP, SHARE_GROUP), Arrays.asList(op));
try (Admin admin = AdminClient.create(adminProperties)) {
admin.incrementalAlterConfigs(configs).all().get();
}
}
Message-level acknowledgement is a key improvement to Kafka, enabling use cases like job queuing which were not well supported before. At the same time, the feature still feels relatively basic at this point.
Most importantly, there’s no notion of a dead letter queue (DLQ) as of the Apache Kafka 4.0 release. Once an unprocessable message has been archived, there’s no way of identifying it. For many use cases it will be required to either have means for retrieving the unprocessable messages with an offset smaller than the SPSO or, better yet, to have bespoke DLQ support, i.e. a dedicated topic to which unprocessable messages are sent automatically. In scenarios where there’s a dependency between messages with the same key, it would also be desirable to send all subsequent messages to the DLQ once one message with a given key got DLQ-ed, until that issue has been resolved. As of today, this is something you’d have to build entirely yourself.
Another useful enhancement would be more flexible retrying behaviors. In the current form of Kafka queues, a released message will be retried immediately; there’s no support for delaying retries (e.g. via exponential back-off) or configure a scheduled redelivery. This means that all available retry attempts will happen very quickly, which isn’t ideal for dealing with transient failures such as not being able to connect to an external service. Retrying within a short period of time may not be useful in this situation, while retrying after 30 or 60 minutes could.
All that being said, the support for queue semantics in Kafka 4.0 is an early access feature after all, and I’m sure all kinds of improvements can and will be made in subsequent releases. In particular, DLQ support is explicitly being mentioned in the KIP as a future extension.
Retry Behavior and State Management
Let’s dig a bit deeper and explore how retries are currently handled by the share group API. To do so, I’ve built a share consumer which processes some messages as shown in the in-flight records example in the KIP:

The messages on the topic have a String value which matches their offset: "0", "1", "2", etc. The process logic looks like follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
System.out.println("Record | Status | Delivery Count");
System.out.println("--------------------------------");
while (true) {
ConsumerRecords<String, String> records = consumer.poll(
Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
String status = switch(record.value()) {
case "1", "5" -> {
consumer.acknowledge(record, AcknowledgeType.ACCEPT);
yield "ACKED";
}
case "3", "7", "8", "9" -> {
consumer.acknowledge(record, AcknowledgeType.RELEASE);
yield "AVAIL";
}
case "6" -> {
consumer.acknowledge(record, AcknowledgeType.REJECT);
yield "ARCHV";
}
// doing nothing, i.e. remain in Acquired state
default -> {
yield "ACQRD";
}
};
System.out.println(String.format("%s | %s | %s",
record.value(), status, record.deliveryCount().get()));
}
consumer.commitSync();
}
Starting from the beginning of the topic, here’s the output of the first polling iteration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Record | Status | Delivery Count
--------------------------------
0 | ACKED | 1
1 | ACKED | 1
2 | ACQRD | 1
3 | AVAIL | 1
4 | ACQRD | 1
5 | ACKED | 1
6 | ARCHV | 1
7 | AVAIL | 1
8 | AVAIL | 1
9 | AVAIL | 1
2 | ACQRD | 1
4 | ACQRD | 1
2 | ACQRD | 1
4 | ACQRD | 1
2 | ACQRD | 1
4 | ACQRD | 1
...
The first ten lines—corresponding to the first batch returned by the poll() call—are not too surprising: all messages are processed as expected. But then something interesting is happening: messages 2 and 4 (but not messages 3, 7, 8, 9 in Available state) are retrieved again and again. As it turns out, messages in Acquired status are returned indefinitely by poll() until they are acknowledged. This happens purely client-side, i.e. reaching the broker-side maximum lock duration (configured via group.share.record.lock.duration.ms, defaulting to 30s) does not cause an interruption here, which may be surprising. Also note that the delivery count is not increased in this case. After speaking to the engineering team working on this team I learned that exact behaviors and semantics are still in flux here—the API is marked as unstable at this point—so you probably are going to see some changes here with the 4.1 release.
Only when actually acknowledging a message and trying to commit after the maximum lock duration has been reached, an exception is triggered. It is not actually raised though; instead you need to examine the partition-exception map returned by commitSync():
1
2
3
4
5
6
7
Map<TopicIdPartition, Optional<KafkaException>> syncResult = consumer.commitSync();
System.out.println(syncResult);
// output adjusted for readability:
// { [.underline]#oj_vK_XvQeSrL58aI81r1g:my-topic-0=Optional[org.apache.kafka.common.errors.InvalidRecordStateException# :
// The record state is invalid. The acknowledgement of delivery could not be completed.]}
Note that this affects all the messages on that share partition whose acknowledgement you tried to commit. I.e. also a message which you acknowledged would be retried again in this case.
When running another consumer in the same share group—or when restarting the consumer above—it’ll receive the available messages 3, 7, 8, and 9. Whether it’ll also receive 2 and 4 depends on whether the acknowledgement lock already has expired or not.
Share Group State Persistence
The state of inflight messages needs to be made durable by the share-partition coordinator. This responsibility is handled through a component called the share-group state persister ; While the KIP mentions that his could be a pluggable component eventually, there’s only a single persister implementation right now. It stores the state of share groups in a special Kafka topic named __share_group_state.
There are two kinds of records on that topic, ShareSnapshot and ShareUpdate records. The former represents a complete self-contained snapshot of the persistent state of a share-group, whereas the latter represents an incremental update to that state. An epoch field in the records is used to fence off writes by zombie share-partition leaders. Upon start-up, the coordinator reads the entire topic and builds up the state for a given share-partition. It does so by finding the latest snapshot record and then applying all subsequent updates. As such, the share group state topic isn’t suitable for Kafka topic compaction (i.e. keeping only the latest record with a given message key). Instead, the coordinator itself deletes all records for a share partition before the latest snapshot record.
To take a look at the __share_group_state topic, you can use the standard Kafka console consumer; just make sure to use the class o.a.k.t.c.g.s.ShareGroupStateMessageFormatter as a formatter:
1
2
3
4
5
6
bin/kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--property print.key=true \
--topic __share_group_state \
--from-beginning \
--formatter=org.apache.kafka.tools.consumer.group.share.ShareGroupStateMessageFormatter
Here’s a message describing the state of the inflight messages shown above:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
{
"key": {
"version": 1, (1)
"data": {
"groupId": "my-share-group",
"topicId": "YrHYV-TdRrqvUkvejYQ8Gw",
"partition": 0
}
},
"value": {
"version": 0,
"data": {
"snapshotEpoch": 0,
"leaderEpoch": 0,
"startOffset": 0, (2)
"stateBatches": [
{
"firstOffset": 0,
"lastOffset": 1,
"deliveryState": 2, (3)
"deliveryCount": 1
},
{
"firstOffset": 3,
"lastOffset": 3,
"deliveryState": 0, (4)
"deliveryCount": 1
},
{
"firstOffset": 5,
"lastOffset": 5,
"deliveryState": 2, (3)
"deliveryCount": 1
},
{
"firstOffset": 6,
"lastOffset": 6,
"deliveryState": 4, (5)
"deliveryCount": 1
},
{
"firstOffset": 7,
"lastOffset": 9,
"deliveryState": 0, (4)
"deliveryCount": 1
}
]
}
}
}
| 1 | Indicates this is a ShareUpdate record) |
| 2 | The current share-partition start offset |
| 3 | Status ACKED |
| 4 | Status AVAIL |
| 5 | Status ARCHV |
To manage the state of share groups, the aforementioned script bin/kafka-share-groups.sh can be used. It allows you to list and describe existing share groups and their members, reset and delete their offsets, and more:
1
2
3
4
5
6
7
8
9
bin/kafka-share-groups.sh \
--bootstrap-server localhost:9092 \
--describe \
--group my-share-group \
--verbose
GROUP TOPIC PARTITION LEADER-EPOCH START-OFFSET
my-share-group my-topic-2 0 - 2
Summary and Outlook
KIP-932: Queues for Kafka adds a long awaited capability to the Apache Kafka project: queue-like semantics, including the ability to acknowledge messages on a one-by-one basis. This positions Kafka for use cases such as job queuing, for which it hasn’t been a good fit historically. As multiple members of a share group can process the messages from a single topic partition, the partition count does not limit the degree of consumer parallelism any longer. The number of consumers in a group can quickly be increased and decreased as needed, without requiring to repartition the topic.
Built on top of Kafka’s event log semantics, Kafka queues provide some interesting characteristics typically not found in other queue implementations, such as the ability to retain the messages on a queue for an indefinite period of time, reprocess some or all of them, and have multiple independent groups of consumers, with each group processing all the messages on the topic. For instance, you could have two share groups applying slightly different variants of some processing logic in an A/B testing scenario.
One aspect which I couldn’t explore due to time constraints are the performance characteristics of Kafka’s queue support. It would be interesting to see how the overall throughput increases as more consumers are added to a share group—without increasing the number of partitions—how message-level acknowledgements impact performance, or what the impact of, say, rejecting and retrying every 10th message would be. This would be a highly interesting topic for a follow-up post.
Available as an early access feature as of the Kafka 4.0 release, Kafka queues are not recommended for production usage yet, and there are several limitations worth calling out: most importantly, the lack of DLQ support. More control over retry timing would be desirable, too. As such, I don’t think Kafka queues in their current form will make users of established queue solutions such as Artemis or RabbitMQ migrate to Kafka. It is a very useful addition to the Kafka feature set nevertheless, coming in handy for instance for teams already running Kafka and who look for a solution for simple queuing use cases, avoiding to stand up and operate a separate solution just for these. This story will become even more compelling if the feature gets built out and improved in future Kafka releases.
Voting for the release 4.0.0. RC1 of Apache Kafka just started earlier today, so it shouldn’t be much longer until you can give queue support a try yourself with an official release. To discuss any feedback you may have, reach out to the Kafka developer mailing list.
Many thanks to Andrew Schofield for his input and feedback while writing this post!